Week 5: October 7, 2024
This blog is an ongoing project for Professor Ryan Enos' Election Analytics Course at Harvard College (GOV 1347, Fall 2024). It will be updated weekly with posts analyzing how different features impact the likelihood of Kamala Harris (D) or Donald Trump (R) winning the 2024 U.S. Presidential Election or winning specific states in the election. The blog will culminate in a final predictive model for the outcome of the general election.Context & Question
A [study analyzing errors in 2016 election polling](https://digitalcommons.unl.edu/sociologyfacpub/543/) found that most pollsters overweighted the responses of people who didn't actually cast a ballot on election day. They may have weighted all responses equally, failing to account for people's likelihoods to vote, or they could have weighted responses based on a factor not-related or inversely related to voter turnout. But how would a pollster know if a surveyed subject was "likely to vote." According to the researchers, those most likely to vote were people who owned landline phones! I'm skeptical that the sheer act of having a wall/landline phone in one's home, and walking over to it every time they receive a call makes them likely to vote... but it's possible that there are *other demographic features* of people with landline phones that *also and independently* influence their decision to cast a ballot. These could include age, race, type of residence/neighborhood, and those are exactly the factors that I'll analyze in this week's post! In this post I build a model for predicting the national democratic vote share by creating three likelihoods that people will turnout to vote, based on race, age, and education level, respectively. I code these variables into 4 categories, and one limitation is the 64 distinct combinations of identities that people can possess. It's impossible to predict turnout at the *individual level* from this data, because different voters may be swayed based on *different* elements of their identify (i.e. while one voter may strongly identify and vote alongside people of the same race, another voter may be more encouraged by voters their own age.)The Data
I cleaned datasets for voter age, race, education level, turnout rate, and share of the electorate for all general and midterm elections since 1986. The charts below summarize turnout rate for each category over time:## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.3 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.5.0
## ✔ ggplot2 3.4.4 ✔ tibble 3.2.1
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.0
## ✔ purrr 1.0.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
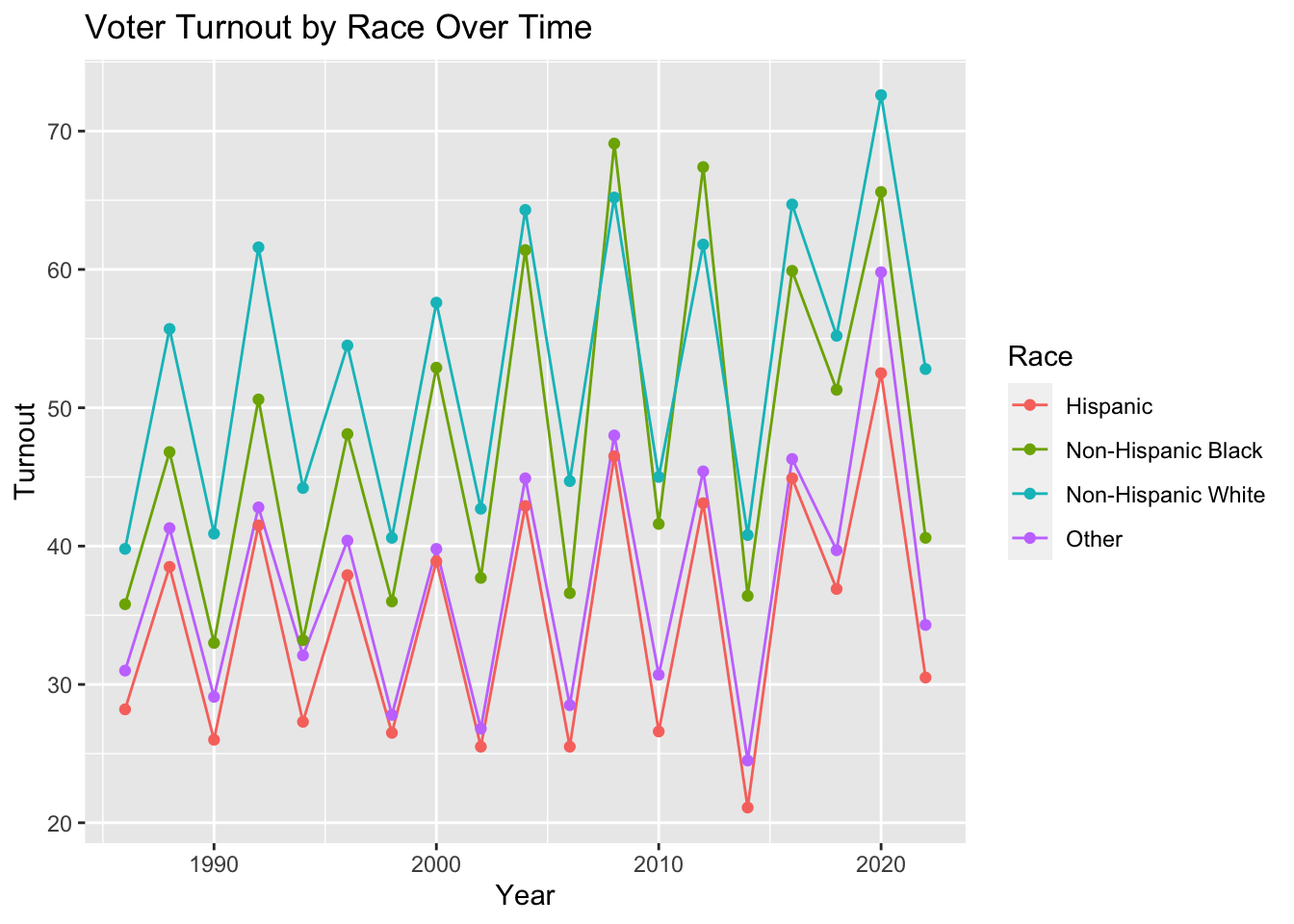
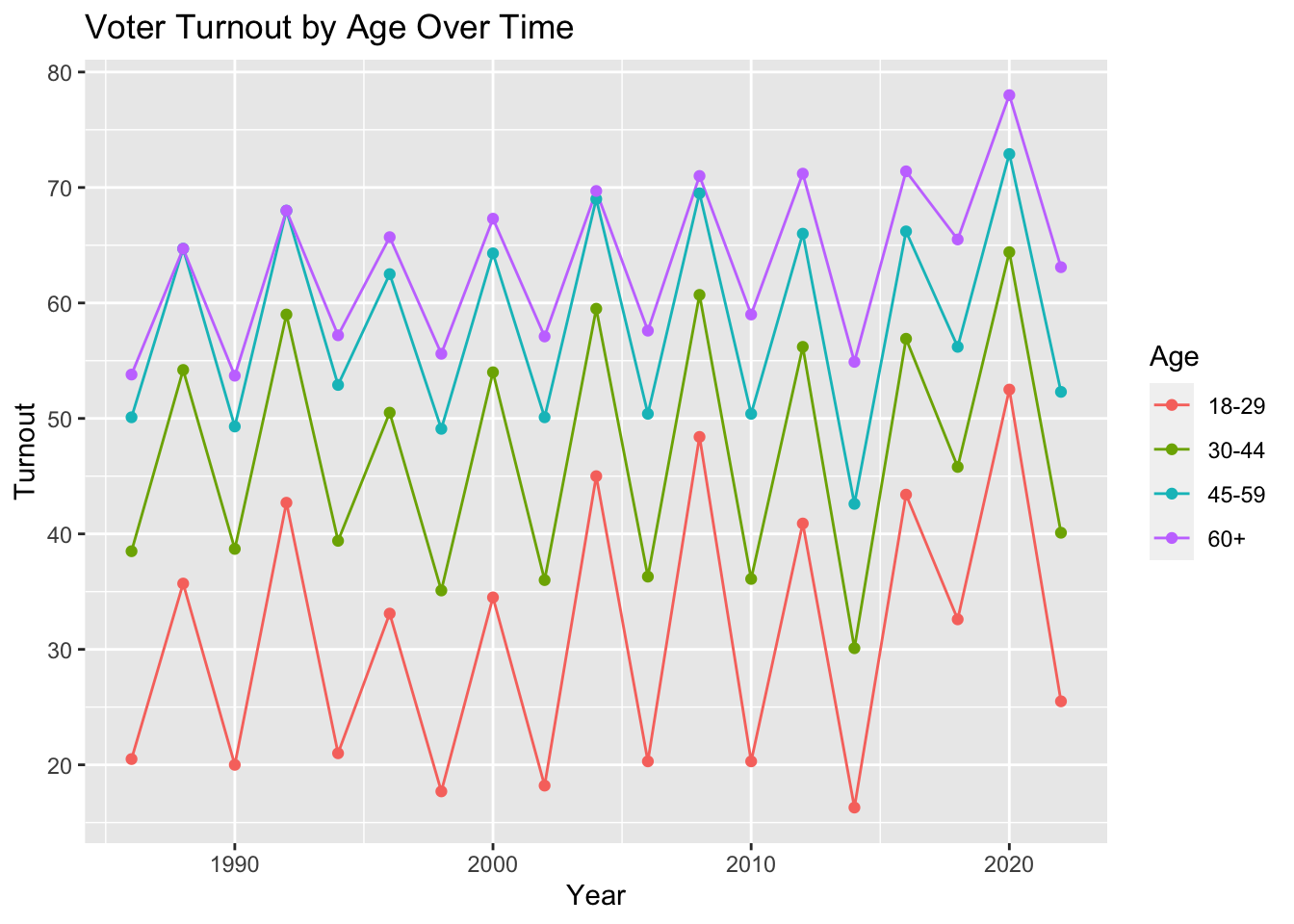
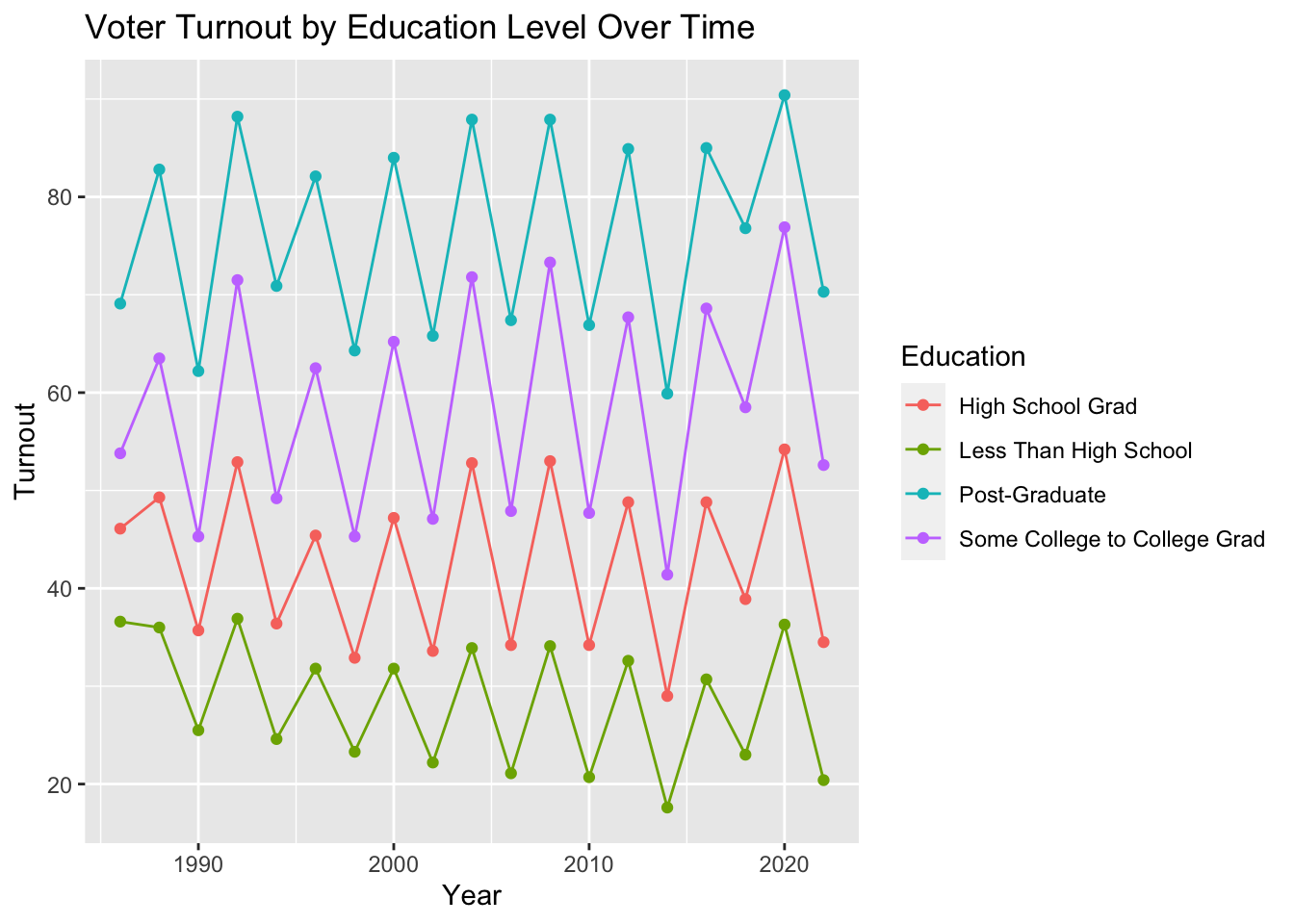
The peaks on the plots above make sense given that this data contains general elections and midterm elections. Turnout tends to be higher, and voters tend to be more excited, across demographics when voting for president as opposed to another office.
I joined these datasets and appended one containing Democratic Vote Share in each of the presidential elections. To reduce the oscillatory effect observed above, I only keep the presidential election data from here forward, but it was informative to see that the trends in turnout prevailed during all election types and years.
Analysis&Results
First, I fit some line plots to see if there were observable relationships between a demographic group's turnout and democratic vote share.## Warning: package 'modelsummary' was built under R version 4.3.3
## `modelsummary` 2.0.0 now uses `tinytable` as its default table-drawing
## backend. Learn more at: https://vincentarelbundock.github.io/tinytable/
##
## Revert to `kableExtra` for one session:
##
## options(modelsummary_factory_default = 'kableExtra')
## options(modelsummary_factory_latex = 'kableExtra')
## options(modelsummary_factory_html = 'kableExtra')
##
## Silence this message forever:
##
## config_modelsummary(startup_message = FALSE)
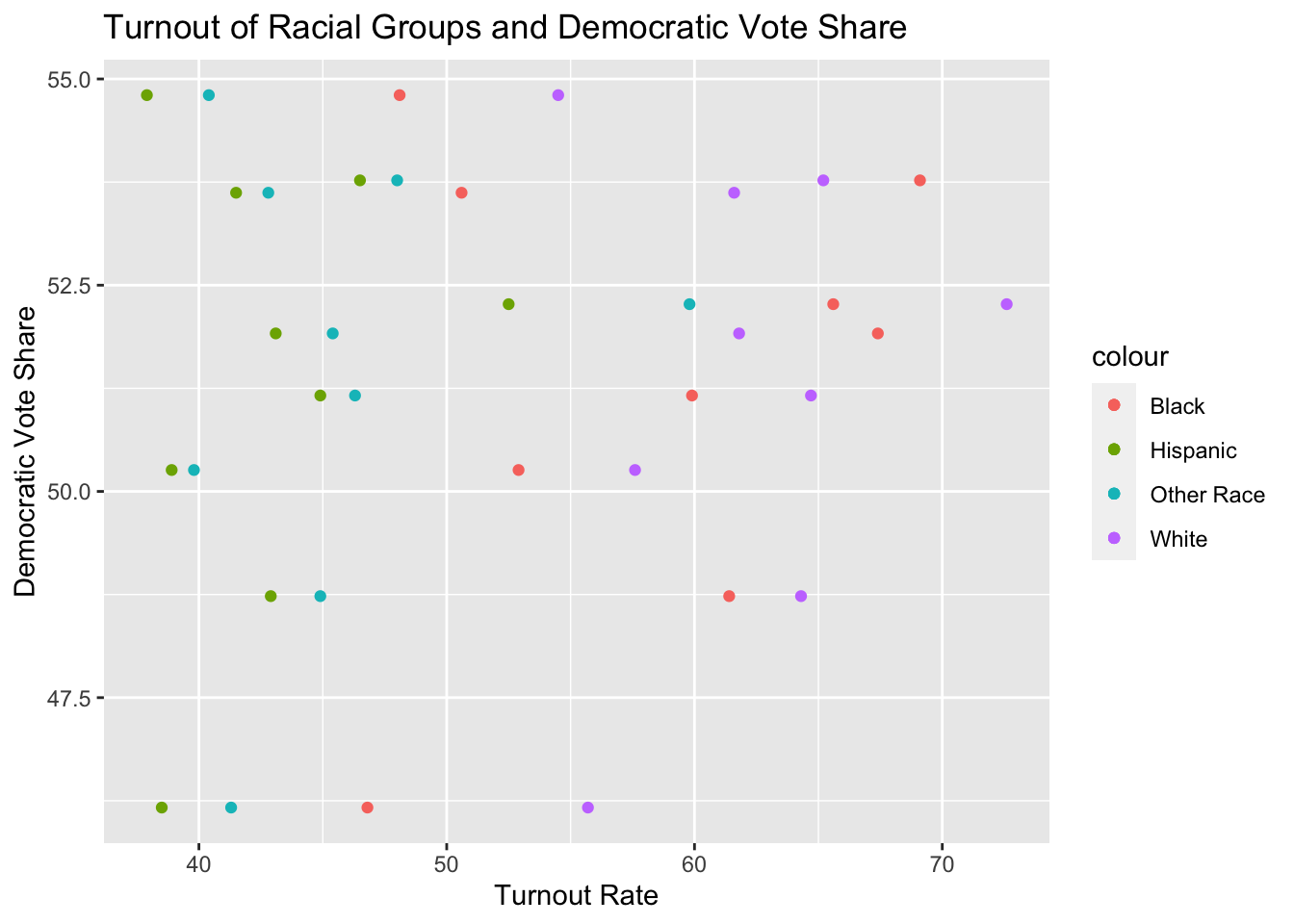
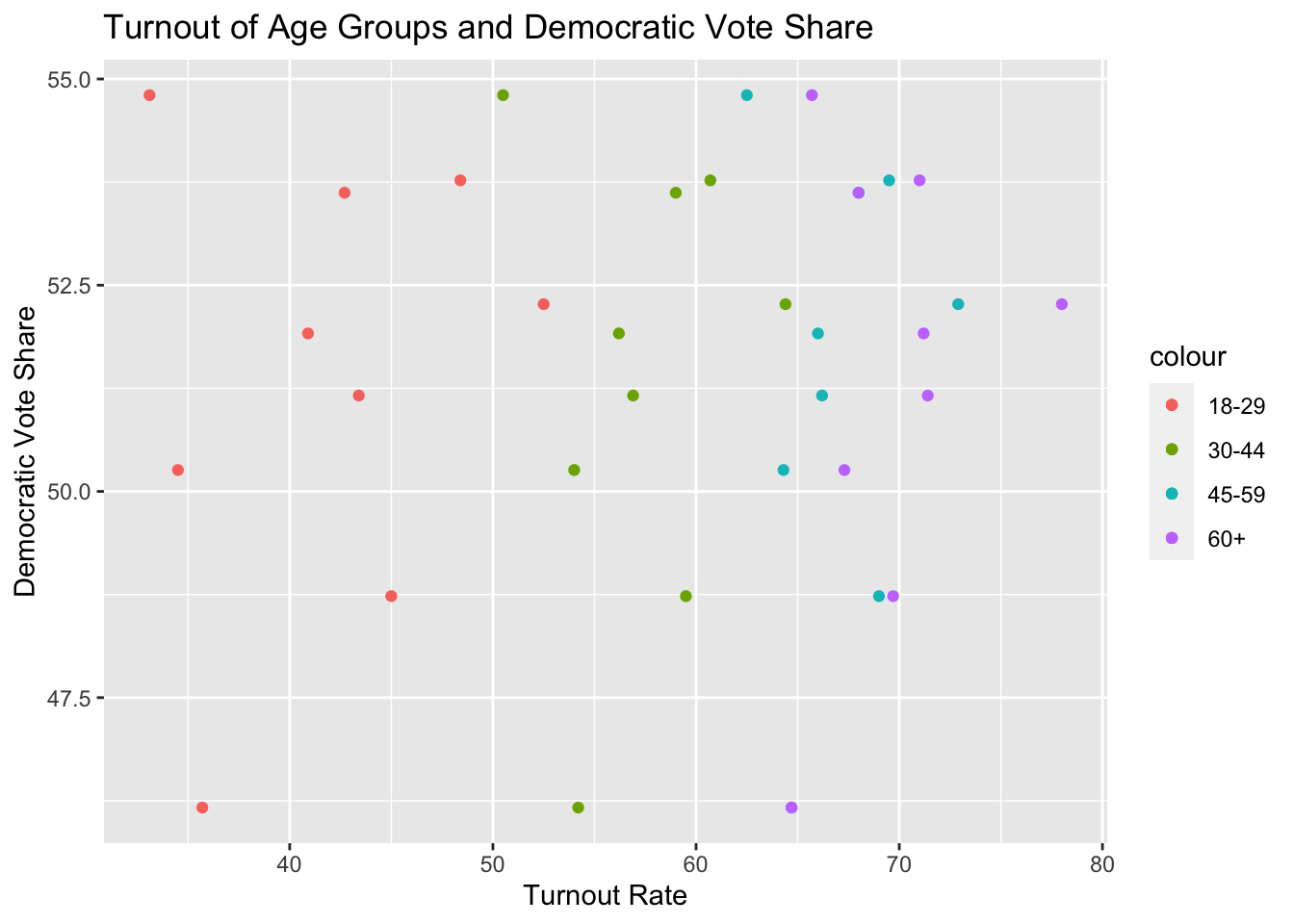
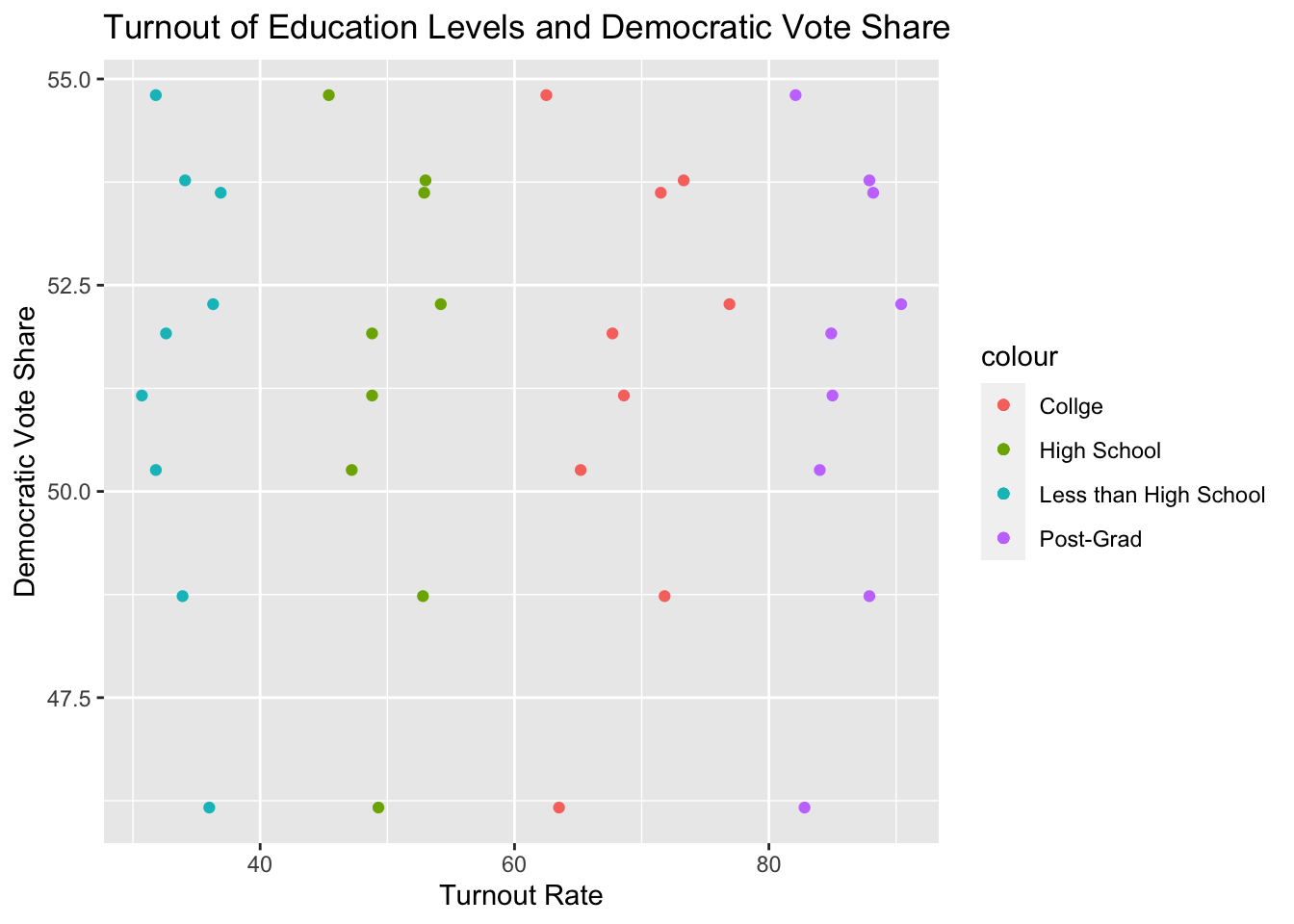
An interesting result of the plots above are that, turnout rates among different education levels are highlight stratified, and that democratic vote share varies despite the differently-educated voters turning out in similar numbers from election-to-election. This indicates that the turnout of a certain educational group is not a good predictor of democratic vote share: The turnout rates of education levels do not vary to the extent that democratic vote share varies, and they certainly do not vary together. Thus, I will exclude education data from here forward.
Next I fit a multiple linear regression to determine which of the remaining 8 predictors (the four races and four age groups) are most predictive of democratic vote share.
##
## Call:
## lm(formula = pv2p ~ Turnout18_29 + Turnout30_44 + Turnout45_59 +
## Turnout60 + TurnoutWhite + TurnoutBlack + TurnoutHispanic +
## TurnoutOther, data = joined_data)
##
## Residuals:
## ALL 9 residuals are 0: no residual degrees of freedom!
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -224.6937 NaN NaN NaN
## Turnout18_29 2.2829 NaN NaN NaN
## Turnout30_44 -3.9131 NaN NaN NaN
## Turnout45_59 5.3562 NaN NaN NaN
## Turnout60 5.7739 NaN NaN NaN
## TurnoutWhite -4.9154 NaN NaN NaN
## TurnoutBlack -0.6944 NaN NaN NaN
## TurnoutHispanic 3.5060 NaN NaN NaN
## TurnoutOther -3.5681 NaN NaN NaN
##
## Residual standard error: NaN on 0 degrees of freedom
## Multiple R-squared: 1, Adjusted R-squared: NaN
## F-statistic: NaN on 8 and 0 DF, p-value: NA
To hone the model even further and reduce the effect of the intercept, I’ll focus on the most salient predictors, which were turnout of people aged 45 and over, the White turnout, and the turnout of Hispanic and voters belonging to “Other” racial groups. It’s worth noting that, on the whole, age group turnouts served as better predictors of democratic vote share than racial turnouts.
##
## Call:
## lm(formula = pv2p ~ Turnout45_59 + Turnout60 + TurnoutWhite +
## TurnoutHispanic + TurnoutOther, data = joined_data)
##
## Residuals:
## 1 2 3 4 5 6 7 8
## -3.28382 3.07793 3.75817 -1.61891 -0.61772 -0.03593 -1.49750 -0.06759
## 9
## 0.28537
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -26.3550 121.7681 -0.216 0.843
## Turnout45_59 0.8239 1.7910 0.460 0.677
## Turnout60 1.4254 2.0574 0.693 0.538
## TurnoutWhite -1.8223 2.0907 -0.872 0.448
## TurnoutHispanic 2.0391 2.3220 0.878 0.444
## TurnoutOther -1.1315 1.2514 -0.904 0.433
##
## Residual standard error: 3.638 on 3 degrees of freedom
## Multiple R-squared: 0.3271, Adjusted R-squared: -0.7943
## F-statistic: 0.2917 on 5 and 3 DF, p-value: 0.8909
When we take out other, extraneous predictors, the effects of the remaining 2 age groups and 3 racial groups become closer to each other. When there is higher Hispanic turnout, Democrats tend to perform better. The same is true for higher turnout of people above age 45. But for higher White turnout and turnout of “other” racial groups, Democratic candidates tend to perform worse.
With data about the likelihood of different age groups and racial groups voting in 2024, the correlations found here could be employed to predict Democratic Vote Share. Such polls, about individuals’ voting plans/mail-in ballot status are important and I hope to see them increase as voter registration deadlines in multiple states come up this week and we keep nearing the election. Overall, estimating candidate performance based on polls and demographics is not effective if the people polled do not turn out to vote, so an investigation such as this one, about candidate performance at various turnout levels among demographic groups can be combined with predictions of the propensity to vote for people in the demographic groups for better candidate performance predictions.